
Deep Dives #5 - Foundation Models and AI Landscape

Hello!!!
I know, it has been a while. Since the last time we met, following things have happened:
ChatGPT became a thing. A big thing.
Adani-Hindenburg-Bharat Desh-Soros-Rahul Gandhi-NaMo circlejerk.
Microsoft declaring open season on Google’s search business. Also, who knew Microsoft made so much money from Bing? which led to…
Google losing $100bn in market cap thanks to the bard.
Aussies folding like a cheap - well, folding chair in the test series.
I was invited earlier this month to a “fireside chat” as a speaker. My insistence on having an actual fire at the venue was not appreciated. I met some really smart founders, but I left the event horrified. If you are in fintech, please, for the love of god, understand the difference between risk and uncertainty.
In other news, I have officially given up on my fundraise. So if anyone is looking to hire a steely eyed investment professional - reach out. I am looking.
Context:
My inbox of late has been full of AI startups. 99% can be described thus - slick UX, API calls to an LLM (like ChatGPT), some prompt engineering. ZERO moat. Valuation expectations are unhinged (and this is the most polite word I can use for them).
Now, this got me thinking - what are the opportunities actually available that may prove to be durable? Turns out, there is a lot of boring picks and shovels style companies that are quietly going about their business. Deep moats, defensibility, deep technical capital.
So, today, I thought we will take a deep dive and look at the world of foundational models and see what rainbows are hiding pots of gold.
1. What is a Foundation Model?
A foundation model is a model that you can build on top of. That is it. That is the definition.
Historically, AI models have been task oriented. While using AI systems to solve real world problems is not a new thing - creating and deploying these systems takes a lot of time and resources. Each application requires a specific, clean dataset. Then you have to train the AI model on the dataset before anything useful can come out of it.
The current wave that AI is riding is about replacing task-specific models with models that can be trained on unlabelled, messy datasets. The models need to be able to manage the learning with minimal tuning and should be able to handle multiple use cases. These are foundation models.
GPT-3, BERT, DALL-E are all examples of Foundation Models. Input a short prompt and the system will generate whole paragraphs or complex images - even when it most likely wasn’t trained to generate content in that manner.
What makes these systems “foundation models” is that they can serve as the foundation for multiple use cases / applications. The key here is self-supervised learning and transfer of learning. The model can apply information from one situation to another. Think of it as how learning to drive a car will give you some basic understanding of how a truck or a bus would work.
The current pace of activity has been nothing short of insanity. Viral use cases have ranged from code generation and testing (here’s looking at you, copilot), rap battles to passing medical entrance exams.
What has enabled this almost cambrian explosion is the Cloud. Suddenly, we had access to computing power not previously thinkable enabling these models which excel at generalizing and are capable text and image generation, summarization, and categorization. These models are displaying properties of complex reasoning (with knowledge) and robustness.
However, given that these models are expensive to build - we have a bottleneck:
2. Where is the Innovation?
An AI company today faces a difficult choice - ease of building vs defensibility. Here is the dynamic:
Ease of Building: foundation models allow people to create a new app over 2-3 days (used to take months, if not years). But the capabilities are limited to whatever has been exposed as off—the-shelf capability by the overlords of the foundation model. This means that every other one of your competitors also has access to the same feature set. Differentiation does not exist.
Differentiation: developers can choose to extend the capabilities of the underlying model. Build something novel and defensible on top of a model like GPT3. However, the technical chops and the resources needed for something like this are nearly unlimited. Think about it - OpenAI would not be where it is without Microsoft’s backing. If we leave resources aside, the technical depth needed alone is bottomless.
The point is that compelling investment opportunities are likely not in the end-apps but in the larger stack. Picks and shovels people, picks and shovels.
3. The Foundation Model Stack:
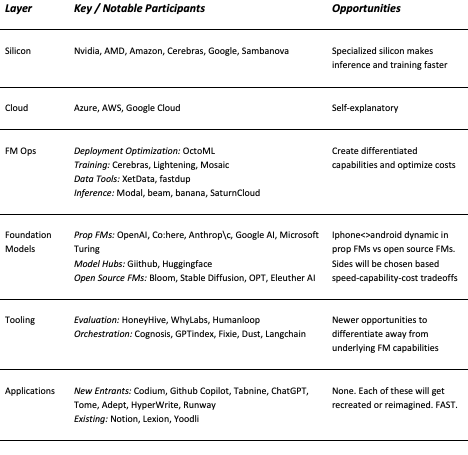
This stack offers 3 broad areas of opportunity:
New applications.
Differentiation
Build tools.
Guess which one I am partial to?
4. Opportunities:
In my opinion - the best opportunities lie in the following areas:
Orchestration:
The state of the art in this area is rapidly combining things like context across calls, prompt engineering and daisy-chaining multiple models in sequence. These are critical drivers for building larger, more useful applications around foundation models. The ease of getting started is something I would have found unimaginable when I graduated in 2006. Here is an example of starting code from LangChain:

That is all it takes. Oh, and BTW, we can very easily replace the underlying FM in a heartbeat. What this means is effortless development - leading to some very solid ecosystems and flywheels.
Evaluation:
As the ChatGPT gaslighting incident shows, foundation models still need to be treated like toddlers. It is hard to predict what they would say or do. This poses a significant risk to nascent businesses. One mouthy AI model can wipe away billions in Market Cap1. This is a risk one can’t necessarily mitigate. Developers are increasingly paying attention to this.
While many benchmarks (like HELM) exist for this purpose, they are not necessarily catch-all solutions because they aren’t designed to address peculiarities of specific use cases or specific user populations. HoneyHive and HumanLoop are two companies that are great examples of solutions that allow developers to iterate the underlying architectures, add novel training sets, modify prompts and improve inference performance. This area will see the emergence of at least a couple of large, generalized businesses and a whole bunch of industry focused, specialized, highly profitable shops.
Training:
Training has proven to be one of the more resource intensive areas of AI stack. I remember reading an estimate that any half decent FM will take ~$10mn in resources to train. A very large part of that cost is finding the training data. However, resources are fast emerging to tackle this problem and bring the cost down to about $500k-1mn range. AI developers today can access some of the best open source architectures on HuggingFace. They can use infra from Cerebras and MosaicML to train the models at scale. They can use fastdup and xethub to curate and organize data sets and finally, they can actually access very large datasets from companies like LAION (images), Common Crawl (web crawler data) and PILE (language texts). These are at their heart - hardcore data businesses - with all the benefits that come from being one2.
Deployment and Inference:
While training costs have dropped sharply - inference3 costs have not. Part of this has to do with the fact that there are really only 3 cloud providers - and they loathe letting anything affect their economics. Part of this has to do with the fact that while training is a one-time style thing - each marginal call on the model runs inference instances. If training the fixed cost - inference is the variable cost. Most of the compute cost of a FM ends up in inference, not training. The impact of these costs is felt in the constraints it puts on the kinds of business models an app-builder can choose. Monetization strategies have to keep a close track of inference costs. However, there are new companies emerging to challenge the big 3 cloud providers. Modal Labs, Banana, Beam, and Saturn Cloud, are hosted inference providers who are aiming to make inference more cost-effective than running directly on a hyperscaler solution (i.e. AWS, Azure, or Google Cloud).

Conclusion:
Eschew moatless end-apps. They will get commoditized or replicated very quickly. Instead, this observer believes that the best returns in AI will come from the enabling infrastructure.
A picks and shovels strategy is also a necessity to maintain equity. It will keep the innovation flowing and to create guard-rails around the ethics and real world consequences of increased use of AI. Concentration of power / resources is a very, very bad thing in this area.
Interesting Reads:
The man himself, Stephen Wolfram (yes, creator of Wolfram Alpha) on how LLMs work. Easy to understand and very well written. (link).
David Birch’s interesting take on digital wallets as identity (link).
Jordan Tigani’s (highly) controversial piece on Big Data being irrelevant (link).
Housekeeping:
As always, I look forward to hearing from you. If you liked this post, pls feel free to share this or subscribe to this newsletter using the links below. While I have been tardy of late, I try to write a 1000-2000 word essay once every 4 weeks or so.
Cough cough google cough cough
https://en.wikipedia.org/wiki/Inference_engine