

Hello, it’s been a while.
Writing this one took time and a fair bit of research.
Today, I thought we’ll take a look at hard core data businesses. I think they represent a compelling opportunity that has not even been scratched - let alone explored in detail. Here is some food for thought:

Of course, the business we are talking about is Bloomberg, and it is as much as a SaaS business as I am a olympic athlete. However, the observation is largely on point. Bloomberg is the gold standard for its industry.
If you look at the tech news of the day, you will see that a few business models have been the “in” thing for the past 36 months or so. SaaS, BNPL, D2C, e-commerce (and whitespaces like logistics) and so on. These have been analysed to death and enough pontificating has happened (including here) on the dynamics, pitfalls and other lurid details.
All of this is made possible by some very deeply embedded data and DaaS businesses (yes, Google is one, as are Facebook, Nielsen, JustDial and even Bloomberg). What we are talking about is deeply integrated, highly defensible, dominant business models that have extremely wide moats, network effects and optionalities.
Great Data Companies will often look like a cross-breed of a SaaS platform (e.g. Salesforce) and Compute services (e.g. AWS). And because they don’t look like enough of either, they are harder to evaluate from an investment perspective.
I am not going to go into specific companies. VC is a business of prospecting, and I have no intention of putting my prospects on parade. I will however, try to give insights from my study of this space and use high level examples. This is much more an exercise in thesis and case building than an investment recommendation.
1. Defining a DaaS business
A “DaaS1 or Data Company or a Data Business” has as its core product, data. Remove the data, and you don’t have a business. This data can be stock prices (Bloomberg), local businesses and classifieds (JustDial) or even something as banal as restaurant menus (Foodiebay, precursor to Zomato). The access to this data may be free, or for a one time fee, pay as you go or most likely a subscription (Bloomberg terminals are a great example).
2. Context / Key Discriminators
I will start with 3 points here:
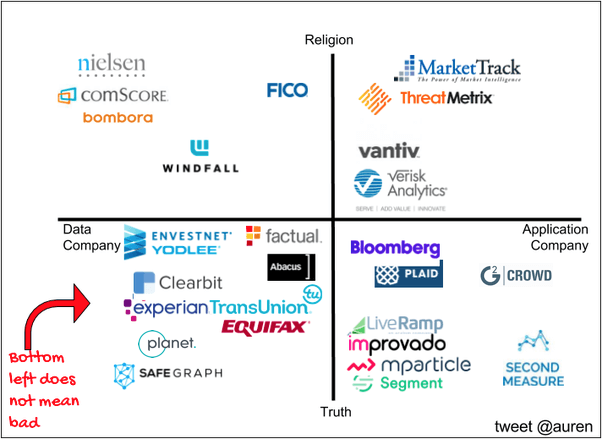
Data Companies are backward looking - they are only supplying information about what has already happened. This is a business of selling verifiable facts. A very useful (and educational) post can be found here, which provides a great framework for looking at Data Companies - truth versus religion and data versus application. Truth companies focus on facts that happened and Religion companies use those facts to help predict the future. Data Companies focus more on selling the raw data while Application companies take the raw data and create some sort of work-flow around it. Here is a great diagram to illustrate this:

Source: Here Accuracy is the Holy Grail. There is a huge trade-off between precision (accuracy) and recall (coverage). An easy trap to fall into is to trade accuracy for coverage2. Mathematically, the more entities one has data about (and the more information about each entity), the less likely that any one data element is correct. The faster the data improves (and the more the company is committed to truth), the more likely the Data Company will win its market. And there are massive gains to winning a market. Which brings us to…
Data is a winner takes most (if not all) business. Dominance will not necessarily result in pricing power - in fact, most successful companies in this position will try to undercut pricing to make it impossible for competitors to survive. however, it is a market share game. You don’t need a fancy UI and a huge AI/ML predictive setup - simply providing accurate data in a clean, easy to use format (API, query-ability, integrations etc) are enough to get to a large market share.
3. Slow beginnings that Avalanche (and why Data Businesses are often bootstrapped)
Like most other things, there is a critical size of a Data Business which it needs to get to - slowly, steadily - before it becomes valuable. Datasets (much like network effects) work on exponential scale. There is a tipping point, a minimum Dataset size below which a nascent Dataset is useless. This is analogous to an minimum viable product in a startup - but a Minimum Viable Dataset (MVD) is harder to build.
Data acquisition methods either rely on existing scale (which we don’t have as a new business) or require up-front money (e.g. for feet on street or for licensing trading data from an exchange).

However, once this notch is hit, the value grows exponentially. There is a whole lot of math involved here about why this is so and which brings in concepts of Information Theory and Entropy but I will steer clear of that. All I would say is that building the Dataset requires significant time and resources.
The effort required to go from zero to MVD in Data Businesses is one reason they are so dominant and defensible. It's also why brute forcing the building by doing it yourself remains a popular entry mode. It is also a sound positioning strategy (more on this in the next section).
Like the proverbial snowball that turns into an avalanche, Data Businesses tend to grow very, very fast once they get past the MVD hurdle:
Marginal costs of acquiring data start declining, often dramatically. Economies of scale start emerging.
As Datasets grows faster (due to lower marginal cost), the audience increases. There is much more of a market for a list of Doctors across India than for doctors just in say - West Bengal.
Wide usage turns the dataset from optional to essential. Aka monkey see, monkey do. New customers start signing up because others are using it.
As you inch closer to being a standard, sales get easier, cycles shorten, generally life becomes easier.
Our pricing power increases. As does profitability (most costs in this are fixed costs, more later).
Stickiness of revenues increases as you can now charge for updates. No one wants to work with old data.
LTV/CAC becomes insane.
Finally - Data starts flowing to you. Now you can start building loopy models like data exchange and affiliates which need a certain scale.
Now, there is a point where the marginal cost of data acquisition starts rising, but you can go a very, very long way before you start running into these edge cases. In the meanwhile, we can sum up the flywheel of a Data Business as a couple of interlocking loops.

4. Building the Data Asset
The best way to look at The Data in such companies is to think about their balance sheets. In a manufacturing company, the most critical thing on their balance sheet will be their manufacturing assets. For a Data Business, the most critical thing on their balance sheet will be the Data which they use to derive economic value from. It is a trade on information asymmetry. This data asset can be proprietary or derived from others on which insights / capabilities have been built. Either way, the Data Asset is the reason to exist.
Now, you can build this dataset in a few ways:

This is by no means an exhaustive list, but covers the big ones.
Build it yourself: Lowest hanging fruit - go and collect the data in the world. It could be Census-takers counting people, Google crawling the entire internet, Justdial sales people bringing businesses onto the platform. Expensive, but quality is assured.
Add Value to Existing Data: You take others’ data (e.g. from disparate sources) and standardize it so its usability increases and requirement for context decreases. A great example would be a business like FactSet and Bloomberg - they take something as dry as financial statements and categorize / standardize it so that end-users don’t have to. It might sound banal and rip-offy but once you become the standard, the moat is crazy wide. Last time I checked, a Bloomberg subscription cost ~1,500-2000 USD per month.
License Others’ Data: Another riff on #2. Here is a website: Screener - all this data is publically available from the exchange, but they (exchanges) make it difficult to use it in any meaningful way. Screener allows a retail investor to get access to old historical data and use it to make trade decisions. Another example that moves away from high finance is Scale. They annotate images and videos. The more data they can get from others, the more they can improve the solution for everyone.
Outsourced / Affiliates: Basically - have someone else get the data for you. Now, this is not about outsourcing field executives collecting data to a temp staffing company. A great example of this will be the Facebook Pixel. People embed this into their websites. FB collects data across multiple sites and is able to use this affiliate relationship to optimize its ads business.
Network Effects: Once you get large enough, data starts flowing into you. A great example of this are search engines. they benefit from queries and from SEO data and eventually don’t have to work exponentially harder to maintain quality at the margins - it is in the interest of others to give you accurate data. Another example of this will be Credit Bureaus. Individuals are motivated to give them as accurate data as they can because it impacts so much of their financial well-being.
Exchange of Data: Think of this one as someone paying in kind (e.g. Google offers App APIs that collect user data for developers, but they also give it to Google as an in-kind payment for building the API) or a data consortium like the GDC where you give your data to get others’ data. Yet another example will once again be credit bureaus. You give your own transaction data to get access to others’ transaction data.
From Operations: This can happen in two ways. You create data from your own operations (e.g. Amazon, Alibaba and the incredibly rich data they have on shopping and searches). Here, the data is in many ways a core business input and pretty much determines what you will do next. Another way to get data from operations is as a side effect. A great example of this is Zomato. Their core business is delivery, but they also pitch the consumer profile data and insights to restaurant owners as a key benefit to joining their platform. The data is quite secondary to deliveries but is still an important part of the whole.
Now, if you have been kind enough to read through here - you might wonder - it is really only 3 ways - why am I trying to claim there are 7? You will see that one morphs into another quite seamlessly. These are mutually reinforcing modes where drawing a boundary (or any boundary for that matter) is tough.
5. Economics of Data Businesses are counter-intuitive
By this time, we can agree that Data Businesses are about Category Creation, and that is not an easy thing again. You have to evangelize, help customers derive value, create an ecosystem. Initial sales cycles are long, win rates are abysmal until you hit the MVD stage. Then you grow exponentially.
Now, this is the kind of long-tail business model that VC’s wet dreams are made of. And yet, almost 90% of Data Businesses are bootstrapped today. What gives?
Well, once upon a time, it was easy to attract VC funding for such businesses. Of late, growth rates are the key decision making parameter, and long gestation (but inevitable) businesses aren’t favourites today.
The margins often look very bad in the beginning. Data Companies often have a fixed cost of acquiring (external data) / manufacturing (brute forcing own data creation) the core raw materials. For the most part, those costs sit in COGS (given most GAAP norms globally). So the margins initially can look really bad (and sometimes can even be negative in the first year).
Here’s the funny things - these are usually fixed costs. The COGS does not scale with revenue. It’s either a one time or a fixed cost. As companies go to new markets, costs are just a step function. Even the historical data can have a lot of value. It is buy-once, sell-as-many-times-as-you-can. Gathering the data itself is a significant asset — just the act of compiling the data leads to a “learning curve” moat.
SaaS companies, spend unholy sums on sales, marketing, and customer success. Most have questionable margins once you start digging into the financials and look at marketing and sales costs. In DaaS companies, CACs (Customer Acquisition Costs) tend to decline over time (for the same customer types).
One way to see this is ARR (annual recurring revenue) per employee. Another thing to look at is net revenue per employee. Once the company gets to some size (say $20 million ARR), that metric tends to get better each year unless there is some core strategic investment reason for it to decline. If the ARR/employee is getting better, the business is likely a good one. Companies like Google and Facebook have incredibly high net revenue per employee — to the ballpark of ~$1 million per employee. The best SaaS companies average between $100k and $200k per employee.
7. Control of the Dataset = Wide Moat
Winning in this business is being in control of a unique dataset. So if one’s business is entirely built up on someone else’s data: a) they are not a Data Business; and b) they are an intermediary who will get squeezed.
Now here is the thing - unique proprietary data is usually very limited in size. So it is very likely that a nascent Data Business is really pulling from multiple data sources. The trick then is to have enough value of our own (that is hard to build) on top of the data that we cannot be disintermediated. A large enough transformation of data is effectively equivalent to creating a new data product. In doing this, we are effectively creating new information and that is valuable in itself.
We could merge multiple data sources to give rich information (e.g. how many people with credit cards have cars and what cars) that can create substantial value (e.g. for a company like Cartrade). Even something as simple as removing junk or bad entries from data can be a defensible moat.
And for some, they will find that they cannot own data or add transformational value but they can build the tools to let other people make sense of their own data. Hint - its also called Big Data. Here are 40+ companies to look at.
An analogy can be drawn from the Oil industry - drilling equipment makers and service providers (e.g. Schlumberger / big data companies) make a lot of money, refiners even more (Aramco, Reliance, BP / data transformers), but the real people who control the market are the ones who own the oilfields (Saudi Arabia / data controllers).
Once we have our flywheel going for our Data Business, we need to get to market share dominance in our niche. The goal should be to get to over 50% market share. E.g. LiveRamp, has over 70% market share in its niche.
One way to get to 50% market share is to go after a very small niche and relentlessly focus on it. Of course, we will eventually need to move to adjacent niches.
Another way to dominate market share is via aggressive pricing. For SaaS cos, this is usually not possible because CACs are too high — so lowering LTVs, even temporarily, is usually not an option. But with DaaS companies, CACs can be low and one can find ways to get them lower over time.
Once we have traction, a third lever to get to market share dominance is via acquisitions. SaaS companies have lots of trouble acquiring their competitors. That’s because SaaS companies have a UI — and merging those workflows is incredibly hard to do (and almost never done right). When SaaS companies acquire, they tend to acquire other products in adjacent spaces so they have more products to sell their current customers (to increase LTVs per customer). This has been an incredibly successful strategy for the likes of Oracle and Salesforce. Of course, Data Companies can also acquire new products to sell into their customers. But DaaS companies have an additional opportunity to acquire direct competitors. These DaaS acquisitions have the potential to be much easier to be successful3 because they can just acquire the customer contracts (this is especially true if they already have the superior product). For instance, if there are two companies selling pricing data on stock tickers, combining those offerings is pretty simple — it is basically just a matter of buying the customer relationships and the ongoing associated revenues.
The goal of getting to market share dominance is not to increase prices on our customers. On the contrary. The goal is to lower our CACs so we can lower prices for our customers. CACs go down because there is one dominant player. LTVs go down too because prices drop. But LTV/CAC ratios don’t go down (if anything, they usually go way up). Great DaaS companies act like compute companies (think AWS) — they lower dollar per datum prices every month or year. So our customers get more value for the money and that value compounds over time.
Housekeeping
If you want to read an absolutely mind-blowing essay on Data Content Loops, head here to Kevin Kwok’s site. It is worth reading.
As always, I look forward to hearing from you. If you liked this post, pls feel free to share this or subscribe to this newsletter using the links below. While I have been tardy of late, I try to write a 1000-2000 word essay once a week.
Data as a Service.
And it is easy to see why earlier stage companies would do so - it may be better in some cases to be a smaller fish in a bigger pond. Why be the biggest fish in a puddle?
and model